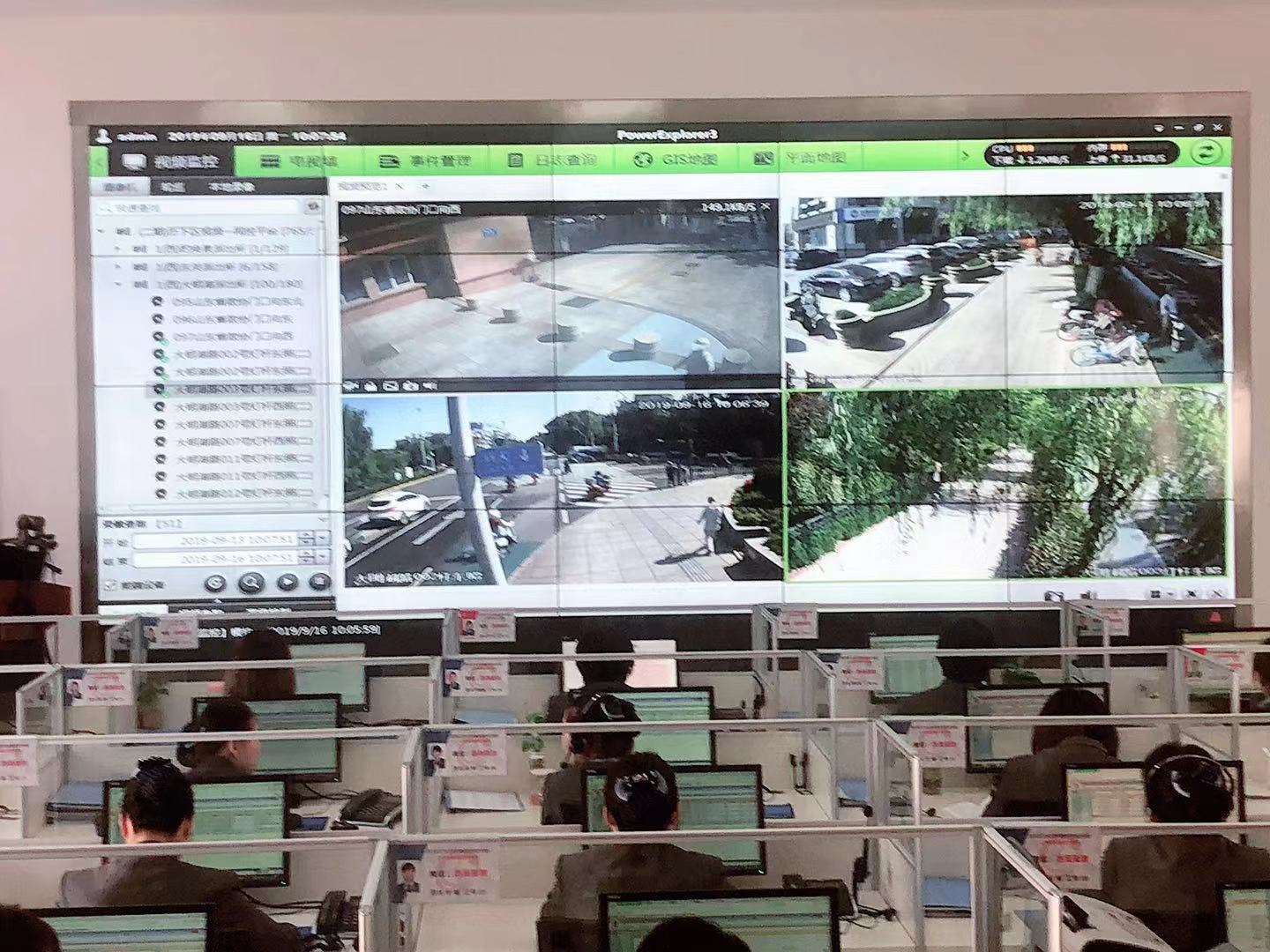
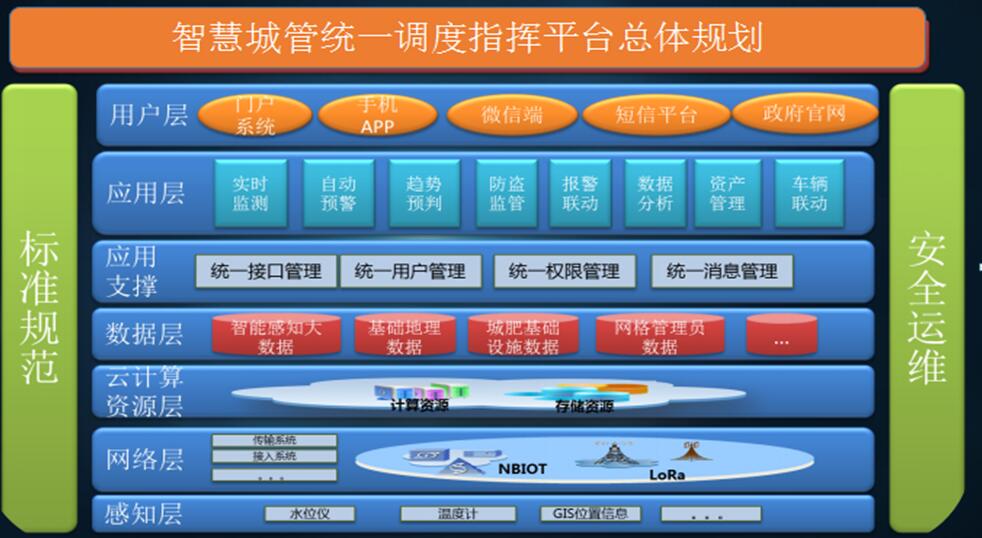
近日,国家网信办发布《生成式人工智能服务管理办法(征求意见稿)》(以下简称《办法》),向社会公开征求意见。自去年以来,生成式人工智能快速走红,席卷文本、图像、音频、视频等各类媒介场景,成为全社会关注的焦点。
生成式人工智能服务以其优异的知识表现、流畅的语言交互和媒介输出,引发了各界的使用和“尝鲜”热潮。威海软件开发今天生成式智能服务背后的核心技术是大规模预训练模型(以下简称“大模型”)。热潮之下,大数据和大模型驱动形成的内容生产模式给科研、生活和伦理带来巨大冲击。
大模型与人类历史上其他科技发明的不同之处在于,发明者第一次无法完全理解人类创造物的具体运行机制,即“黑盒效应”。大规模深度神经网络在训练和使用中,存在结果的不可解释性和不稳定性,这是造成今天伦理焦虑的核心根源。然而这并不能改变大模型作为技术发明的工具属性。在实践上,对待工具有三个层面的要点:以工具视之、以工具用之、以工具治理之。“以工具视之”要求从中性、客观的角度看待新事物。“以工具用之”在于最大限度发挥其优点,规避其缺点。“以工具治理之”的要义则在于将规划和治理目标放在技术使用的行为与场景,而非技术本身。
《办法》的发布无疑是在“以工具治理之”层面迈出了坚实的一步。我国针对语言生成技术和应用的伦理探索和法规规制起步早、发展快。早在2019年年末,北京语言大学、中国中文信息学会等单位向工业界和学术界发布了面向智能内容生成的伦理规制宣言——《推进智能写作健康发展宣言》。2022年,国家网信办、工信部、公安部联合发布《互联网信息服务深度合成管理规定》。而今天,《办法》的起草完成,在过去学术界和司法界探索实践的基础上,综合考虑了近期技术发展与初步应用的特点,与网络安全法、数据安全法等法律相协调,构筑了深度生成服务的管理体系。
用户隐私、内容歧视和模型研发是当前深度生成应用的三个重要法规风险点。《办法》明确,国家支持人工智能算法、框架等基础技术的自主创新、推广应用、国际合作。《办法》集中瞄准技术应用问题,从明确条件要求、划定责任主体等几个方面为行业划定底线。生成内容本身应符合公序良俗和国家法律法规,技术提供方担负内容责任,使用方则应被充分告知其责任,应充分了解智能技术的界限和风险。《办法》对隐私信息这一备受关注的伦理风险点也作出了回应,要求提供方对此做好预防和反馈响应机制。数据资源和预训练模型是生成技术的基础,对此《办法》也要求在技术服务成形的前序阶段就进行法规管制,不得含有违法和有违公序良俗的内容。
法规体系逐步建立是数智时代社会治理的先声与实践。大模型结合大数据,威海软件开发是可预见的未来智能技术落地范式。治理应用、梳理资源是营建生成式智能技术健康生态的重要抓手,这两者也将成为数智时代最重要的政策研究话题。在更高的层面上,人机共生时代的我们还需要关注机器的行为,构建机器行为学,对其语言、传播和物理世界的行为进行研究和探索,以最大程度保障数智时代的社会福祉,收获人机共生的时代红利。
 软件开发行业资讯01/19智慧养老科学与智能工程研究院成立 01/12威海软件开发关键在科技现代化 01/04烟台软件开发为加快建设农业强国强 12/21这一年,烟台APP开发的科技成果振奋 12/14威海APP软件开发公司勇担基础研究重
软件开发行业资讯01/19智慧养老科学与智能工程研究院成立 01/12威海软件开发关键在科技现代化 01/04烟台软件开发为加快建设农业强国强 12/21这一年,烟台APP开发的科技成果振奋 12/14威海APP软件开发公司勇担基础研究重

 软件开发技术01/18烟台软件开发数据科学与智能工程研 01/11统筹推进烟台APP开发科学城体系化建 01/03威海APP软件开发公司民用液氢罐车研 12/19这一年,我们向智慧养老进发 12/13威海APP软件开发公司聚焦数字生态安
软件开发技术01/18烟台软件开发数据科学与智能工程研 01/11统筹推进烟台APP开发科学城体系化建 01/03威海APP软件开发公司民用液氢罐车研 12/19这一年,我们向智慧养老进发 12/13威海APP软件开发公司聚焦数字生态安 公司新闻01/16威海APP软件开发公司打破发展“天花 01/09天津大学纳米中心半导体石墨烯研究 12/22威海软件开发科技创新和产业创新深 12/15烟台软件开发研发投入应统筹兼顾新 12/08加快建设具有影响力的威海软件开发
公司新闻01/16威海APP软件开发公司打破发展“天花 01/09天津大学纳米中心半导体石墨烯研究 12/22威海软件开发科技创新和产业创新深 12/15烟台软件开发研发投入应统筹兼顾新 12/08加快建设具有影响力的威海软件开发