想要了解更多详情欢迎来电咨询18678812288,或登陆网址www.jnwzjs.cn。联系人:王经理。

检察院网络服务大厅软件平台

企业在线考试系统

党员在线考试系统

赢德P2P网贷系统
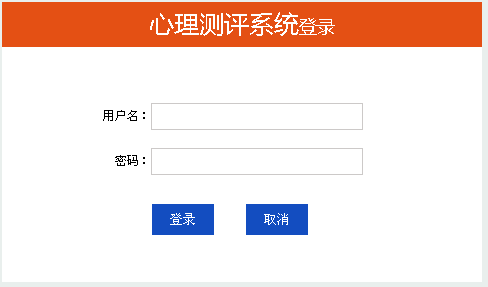
烟台心理测评软件|威海心理测评系
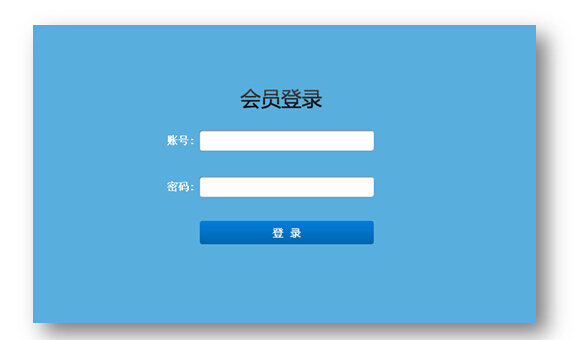
烟台内部培训管理系统|威海出国留

烟台物流软件开发|威海快递软件开

狠刹“四风”网络监督平台软件

党员领导干部德廉知识在线学习测

烟台在线考试系统|威海在线考试软

菏泽新巨龙煤矿采掘资料达标管理
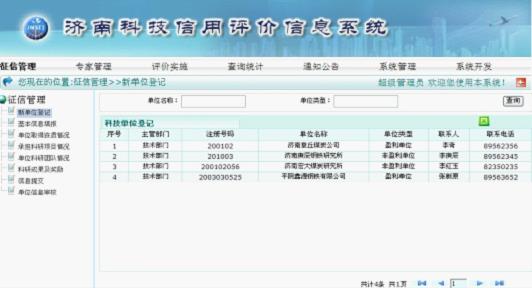
科技信息评价信息系统
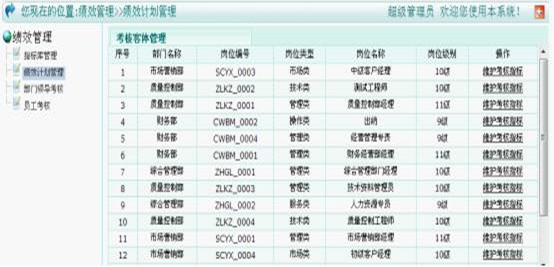
绩效考核系统

济钢炼铁厂管理信息系统
国税房产企业所得税监控管理系统

人力资源管理信息系统

三维数字矿山信息系统
展屏系统

洁能建筑智能管理终端系统

汽修厂管理系统
手机:18678812288 1069706080 版权所有2008-
2018
相关搜索:烟台软件开发| 威海软件开发| 烟台APP软件开发| 威海APP开发| 威海政府管理软件| 威海教育管理APP软件| 烟台政府管理软件| 烟台教育管理APP软件| 烟台手机应用软件开发| 软件开发外包| 游戏软件开发| 威海oa软件开发自学| 我想学APP开发| 如何进行软件开发| 威海软件开发工程师| 威海软件设计| 烟台短信开发平台| 烟台软件开发公司排名| 威海App开发有多难?

 软件开发技术
软件开发技术 公司新闻
公司新闻